
티스토리 뷰
DB 쿼리
데이터베이스에서 사용되는 다양한 쿼리를 정리했습니다.
ALTER
- 테이블을 삭제하지 않고 스키마를 변경
-- 추가
ALTER TABLE <테이블이름> ADD COLUMN <컬럼이름> <컬럼속성> <컬럼이_위치할_순서_위치>;
-- PK 설정
ALTER TABLE <테이블이름> PRIMARY KEY (<컬럼이름>);
-- 삭제
ALTER TABLE <테이블이름> DROP COLUMN <컬럼이름>;
-- 속성 변경
ALTER TABLE <테이블이름> MODIFY COLUMN <컬럼이름> <바꿀속성>;
-- 이름과 속성 변경
ALTER TABLE <테이블이름> CHANGE COLUMN <기존_컬럼이름> <새_컬럼이름> <바꿀속성>;
-- 이름만 변경
ALTER TABLE <테이블이름> RENAME COLUMN <기존_컬럼이름> TO <새_컬럼이름>;
-- 외래키 제약조건 추가
ALTER TABLE <테이블이름> ADD FOREIGN KEY (<컬럼이름>) REFERENCES <외래_테이블>(<외래_키컬럼>);
-- 외래키 제약조건의 삭제
SHOW CREATE TABLE <테이블이름>\G -- 외래키 이름 확인
ALTER TABLE <테이블이름> DROP FOREIGN KEY <외래키_이름>;JOIN
- 두 테이블을 합쳐서 하나로 보여주는 기능
- 닫힌연산이라 여러번 가능
- 크로스조인(cross join)
- 카테시안 곱, 두 테이블의 모든 경우의 수 정보를 합침
SELECT * FROM <테이블명1>
CROSS JOIN <테이블명2>;- 내부조인(inner join)
- 크로스조인 + 조건 필터링
- inner 는 생략 가능
- 세타조인은
<>를 사용하여=이 아닌 모든 경우를 필터링
-- 동등조인
SELECT * FROM <테이블명1>
CROSS JOIN <테이블명2>
WHERE t1.id = t2.id;
SELECT * FROM <t1>
INNER JOIN <t2>
ON t1.id = t2.id;
-- 세타조인: t2 의 id 가 'abc' 인 id가 아닌 것들(즉, = 로 계산했을 때와 반대의 값)
SELECT * FROM <t1>
JOIN <t2>
ON t1.id <> t2.id
WHERE t2.id = 'abc';- 외부조인(outer join)
- 내부 조인을 하면 조건에 맞지 않는 레코드가 사라짐 (조건에 맞지 않는 레코드 까지 보려면 외부조인을 사용해야 함)
- LEFT, RIGHT, FULL 이 있음
- MySql 은 FULL OUTER JOIN 은 지원하지 않는다고 함

join VS union
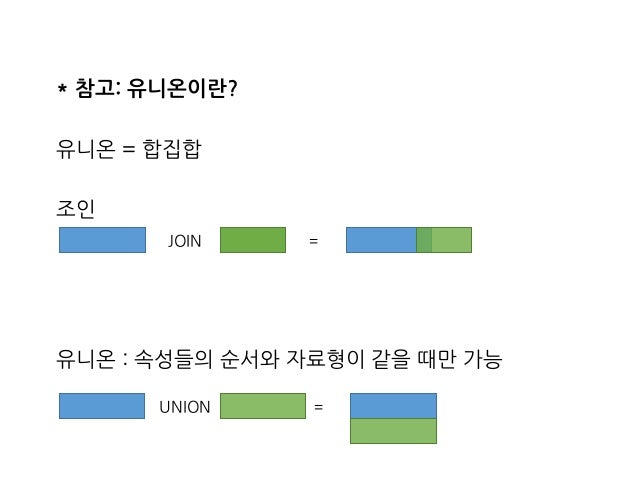
이미지 출처: 호눅스 생활코딩 DB 강의
- 조인은 두 테이블을 합쳐 보여주는 것(다른 속성을 가진 테이블을 같이 보여줄 수 있다.)
- 유니온은 속성들의 순서와 자료형이 같을 때 합쳐서 보여주는 것이다. (두 테이블의 속성들이 일치해야한다.)
GROUP BY
- group by 로 해당 조건으로 그룹을 형성
- group by 뒤에 having 절로 조건 설정 (집합함수는 having 절로만 조건 기술 가능)
WHERE로 필터링 ->GROUP BY로 그룹형성 ->HAVING그룹결과에 대한 필터링- COUNT, MAX, MIN, AVG, SUM 등의 집합 함수가 자주 사용됨
CASE-WHEN
- 하나의 값처럼 동작
CASE <컬럼명>
WHEN <특정값1> THEN <해당할경우_설정할_값1>
WHEN <특정값2> THEN <해당할경우_설정할_값2>
ELSE <그외_설정할_값>
END [AS <별명>]- select 문 안에서 column 값처럼 사용
서브쿼리(nested query)
- 쿼리안에 쿼리가 들어가는 형태
- 중첩쿼리(nested query)라고도 함
- 바깥쪽쿼리: outer query
- 안쪽쿼리: inner query, sub query
- 안쪽쿼리는 무조건 SELECT 문만 가능
- 단일값(스칼라), 하나의 레코드, 하나의 테이블 등이 올 수 있는 자리에 사용가능
- 단일 스칼라값을 대체하는 경우 예시
SELECT * FROM <t1>
WHERE t1.id = (
SELECT <컬럼> FROM <t2> WHERE <컬럼1> = <특정값> LIMIT 1
);- 스칼라 집합의 경우: IN, NOT IN, ANY, ALL 사용
- IN, NOT IN : 포함되거나 아닌경우
- 부등호 + ANY : 하나라도 만족하는 것
- 부등호 + ALL : 모두 만족하는 것
-- in, not in
SELECT * FROM <t1>
WHERE t1.id IN (
SELECT <컬럼> FROM <t2> WHERE <컬럼1> = <특정값>
);
-- any, all (t2의 가격 중 하나라도 큰 경우 참)
SELECT * FROM <t1>
WHERE t1.money > any (
SELECT price FROM <t2>
);- 안쪽 쿼리의 결과물 중에서 바깥 쿼리에서 해당하는 것들을 필터링해서 보여줌
- O(n): m+n
상관쿼리(co-related query)
- 바깥쿼리 테이블의 속성이 안쪽쿼리에서 사용되는 경우
- 바깥쿼리의 한 레코드마다 안쪽쿼리문 전체를 실행하여 만족하는지 확인
- 느림
- O(n^2): m*n
- 가능하면 join 을 사용하는게 좋음
- WHERE 절에서 EXISTS, NOT EXISTS 가 사용되는 경우 많음
- EXISTS: 하나라도 해당하면 1(true)를 반환
- NOT EXISTS: 해당하는 것이 하나도 없다면 1(true)를 반환
-- 2번마켓에서 파는 seller 의 user 의 정보 출력
-- seller 의 정보는 trade 에서, id 정보는 user 에서 옴
SELECT * FROM user
WHERE exists(
SELECT * FROM trade WHERE seller=id AND market_id = 2)
);- FROM 절에서도 서브쿼리를 사용할 수 있지만 반드시
AS를 사용하여 테이블명을 붙여주어야 함 - FROM 절에서는 서브쿼리를 가능하면 사용하지 않는 것이 좋다고 함
뷰
- SELECT 쿼리를 사용하여 만든 가상 테이블
- 용량을 차지하지 않음 (실제 데이터를 따로 저장하고 있지는 않다는 뜻인듯 하다.)
- 만들어 놓은 뷰는 일반 테이블처럼 사용 가능
참고
'Computer Science > DB' 카테고리의 다른 글
| Stored Procedure (0) | 2021.05.21 |
|---|---|
| 트랜잭션(Transaction) (0) | 2021.05.12 |
| 인덱스(Index) 기초 (0) | 2021.05.01 |
| 정규화 (제1정규화, 제2정규화, 제3정규화, BCNF) (0) | 2021.04.22 |
| 데이터베이스 모델링 기초 (0) | 2021.04.16 |
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- DB
- TIL
- 인증
- 우아한테크코스
- CS
- 객체지향
- JS
- 글쓰기미션
- TCP/IP
- 개발공부일지
- 모의면접준비
- 월간회고
- 카카오
- 마스터즈코스
- 내부코드
- JPA
- React
- Transaction
- OS
- 코드스쿼드
- 학습로그
- java
- python
- 회고
- Spring
- 우테코수업
- 운영체제
- javascript
- 알고리즘
- 네트워크
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
글 보관함