
티스토리 뷰
Index
- 데이터베이스의 테이블에 대한 동작 속도를 높여주는 자료구조
- 트레이드 오프가 발생: Read 속도는 빨라지나, Insert, Update, Delete 속도는 느려짐
- 데이터 삽입 시, 외래키를 체크하지 않는 설정:
SET foreign_key_checks=0 - PRIMARY KEY(PK), FOREIGN KEY(FK)에 대해서는 인덱스가 자동으로 만들어짐
- 그외에
CREATE INDEX <인덱스이름> ON <테이블이름>(컬럼이름)으로 인덱스를 만들 수 있음 - 검색이 빈번하게 이뤄지는 컬럼에 대해 인덱스를 생성하기도 함 (읽기 속도 향상)
복합인덱스
- 여러 칼럼을 묶어 인덱스를 만드는 경우에 복합인덱스라고 함
- 여러 컬럼이 같이 검색이 이뤄지는 경우 여러 칼럼을 묶어 인덱스를 만들기도 함
CREATE INDEX <인덱스이름> ON <테이블이름>(칼럼1, 칼럼2)- 복합 인덱스는 순서가 중요
- 첫번째 조건을 기준으로 정렬되기 때문에 첫번째 조건을 활용(칼럼1)하는 경우에 사용
- 두번째 조건으로 탐색한다면 인덱스의 의미가 없음
인덱스의 종류
- 물리적 저장구조에 따라
- Clustered Index
- Secondary Index(Non-clustered Index)
- 논리적 저장구조에 따라
- Unique Index: 고유 인덱스, PK
- Non-unique Index: FK
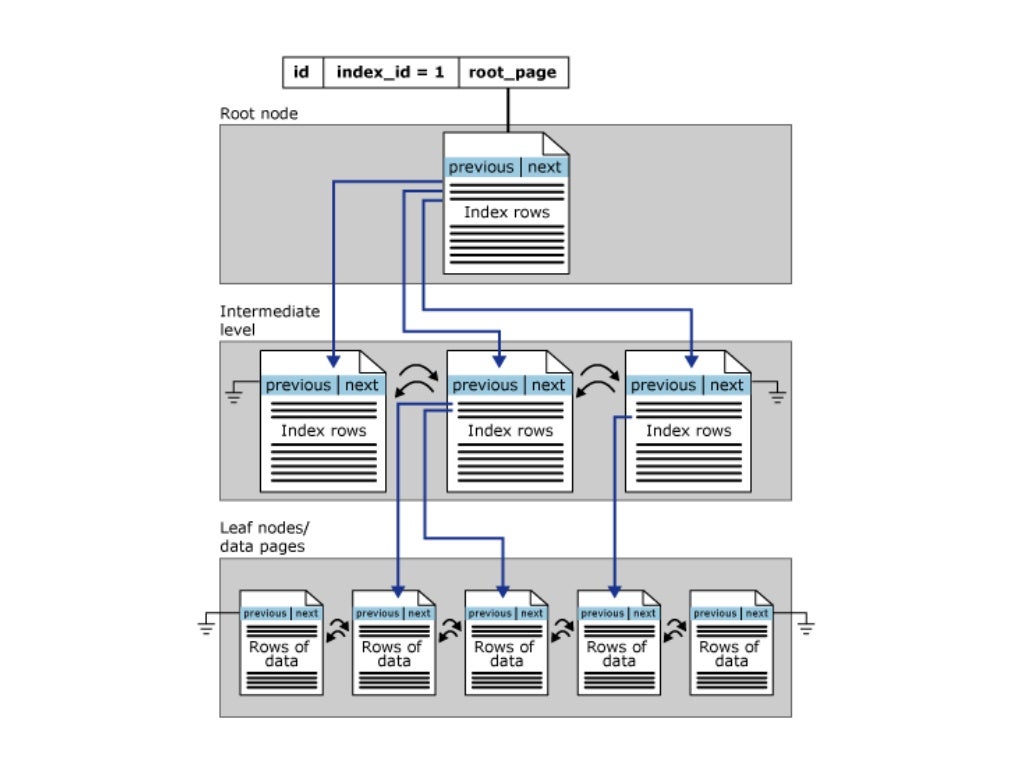
Clustered Index
- Innodb(저장시스템)에서 레코드를 저장하는 방식
- B+tree를 사용
- Key:Value 형태로 저장
- 키: PK
- Value는 하위 노드를 가리키는데 최말단 노드를 리프노드라고 함
- 리프노드: RID(Page Number + Offset)을 가리킴. 이것은 실제 레코드(데이터 페이지) 주소
Secondary Index
- 직접 인덱스를 만들면 secondary index를 생성
- B+tree를 사용
- 키: 인덱스를 생성한 컬럼
- 리프노드: 해당 레크드의 PK를 저장
- 실제 데이터를 찾으려면 두번 인덱스 검색이 일어남
- secondary index로 해당 레코드의 PK값을 찾고
- PK값으로 clustered index를 검색하여 레코드를 찾음
참고
'Computer Science > DB' 카테고리의 다른 글
| Stored Procedure (0) | 2021.05.21 |
|---|---|
| 트랜잭션(Transaction) (0) | 2021.05.12 |
| 정규화 (제1정규화, 제2정규화, 제3정규화, BCNF) (0) | 2021.04.22 |
| 데이터베이스 모델링 기초 (0) | 2021.04.16 |
| RDBMS란? + CRUD 기본 (0) | 2021.04.16 |
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- OS
- 운영체제
- java
- 회고
- 모의면접준비
- 글쓰기미션
- Transaction
- 코드스쿼드
- javascript
- 객체지향
- React
- JPA
- 카카오
- JS
- 우테코수업
- 마스터즈코스
- TCP/IP
- 개발공부일지
- 우아한테크코스
- 알고리즘
- 월간회고
- CS
- 인증
- Spring
- DB
- 내부코드
- 학습로그
- 네트워크
- python
- TIL
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
글 보관함